


Arquitetura de uma solução baseada RAG
Entendendo os principais componentes e procedimentos de uma solução baseada em RAG

Me siga no X | Me siga no LinkedIn | Apoie a Newsletter | Solicite uma consultoria
Aplicações desenvolvidas com LLMs estão ganhando atenção, incluindo cenários como serviços financeiros, onde fornecer informações atualizadas por meio de chatbots de atendimento ao cliente é crucial. No entanto, existem desafios relacionados a capacidades limitadas de resposta devido à informação insuficiente dentro dos LLMs.
Um desses desafios é o fenômeno conhecido como “problema de alucinação”. Esse problema surge quando modelos geram histórias e informações que parecem plausíveis, mas na realidade são fabricadas, pois o modelo preenche criativamente lacunas em seu conhecimento. Isso pode levar a situações em que informações plausíveis, mas incorretas, são geradas.
Para enfrentar esse e outros desafios (como o alto custo do processo de treino destes modelos), foram propostas diversas estratégias, como o aprimoramento de LLMs com novos dados (conhecido como fine-tuning) ou a injeção direta de informações no contexto do prompt. Enquanto que a primeira abordagem acarreta custos significativos, a segunda abordagem de incorporar todas as informações dentro de nos prompts não é prática, devido ao limite de tokens.
Como alternativa, pesquisadores introduziram o modelo RAG (Retrieval-Augmented Generation). Este modelo armazena informações em bancos de dados e recupera as informações necessárias para fornecê-las ao LLM quando necessário. Ao fornecer aos LLMs perguntas relevantes e materiais de referência associados com antecedência, o modelo utiliza essas referências para gerar respostas mais precisas e confiáveis.
Neste texto, exploramos em detalhes uma arquitetura genérica que utiliza o modelo RAG, que pode ser empregada em diversos produtos baseados em LLMs.
Arquitetura de uma solução baseada em RAG
Um arquitetura baseada em RAG geralmente é composta por uma série de bibliotecas e procedimentos. O diagrama abaixo ilustra o processo de utilizar LLMs para receber informações de documentos em alguns passos-chave.
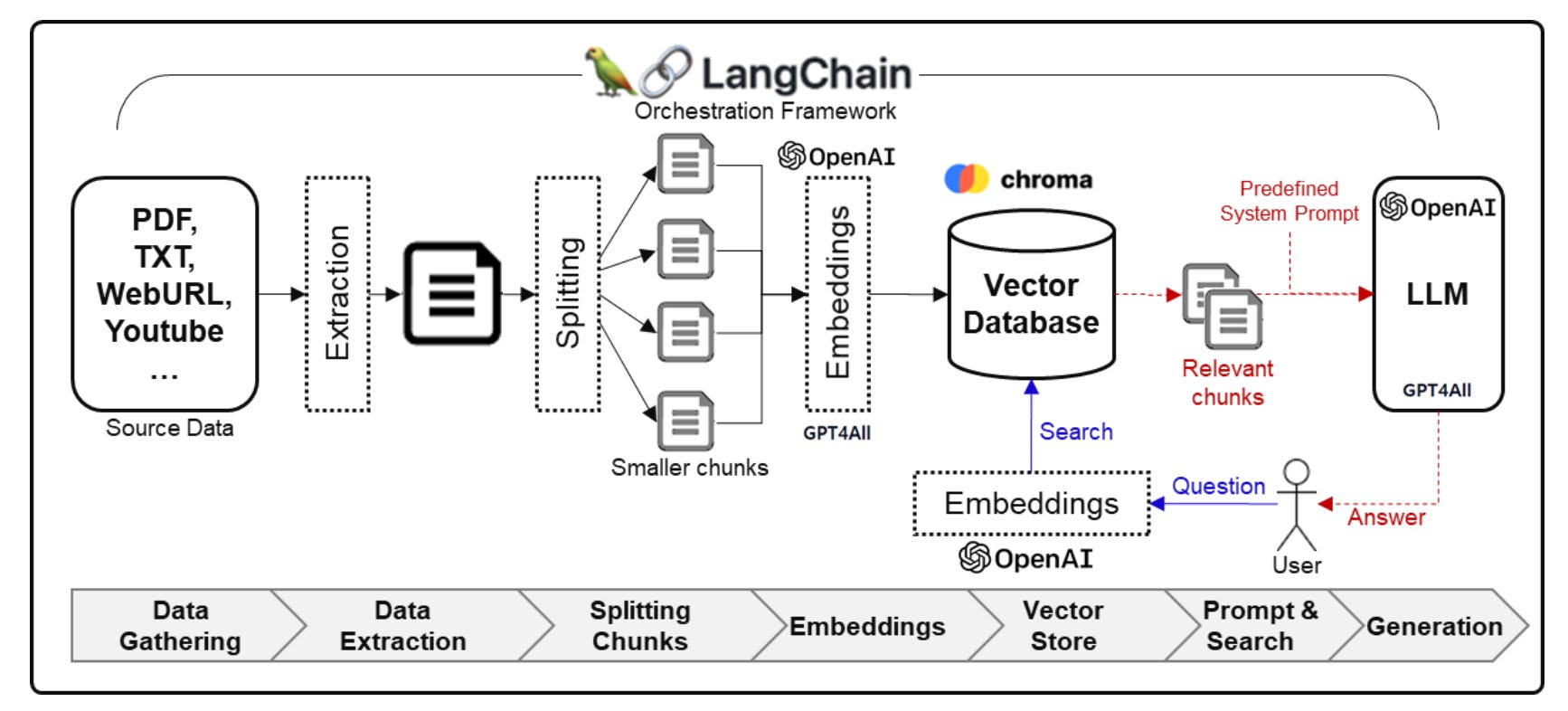
Bibliotecas e frameworks
Para a estrutura geral de orquestração, um framework comumente adotado é adotado o LangChain. LangChain é uma biblioteca que permite a integração e orquestração de diferentes LLMs, banco de dados, e demais ferramentas que apoiam na construção e geração de respostas contextualizadas.
O LangChain, no entanto, não é capaz de gerar novos conteúdos, mas é capaz de integrar com LLM capazes de gerar conteúdo. Para realizar essa tarefa, uma opção seria usar uma combinação de modelos da OpenAI e do GPT4All. Com relação aos modelos, o GPT-3.5-turbo, da OpenAI, tende a ser uma opção adequada quando se compara custo e benefício.
Por exemplo, o GPT-4 tem custo muito mais elevado. Um outro fator a se levar em consideração é que o GPT-4 tem tempo de resposta mais elevado que o GPT-3.5-turbo, o que pode ser um problema de usabilidade, dependendo do tipo de aplicação a ser desenvolvida.
Para armazenar os dados, que serão futuramente consultados e enviado como prompt para o LLM, se utiliza um banco de dados vetorial. Uma opção de banco de dados vetorial é o Chroma DB, que já possui integração nativa com o LangChain, facilitando seu uso e implementação.
Procedimentos
Os principais procedimentos da estrutura são detalhados a seguir.
1) Coleta e Extração de Dados Fonte: Durante a fase de coleta de dados, dados estruturados e não estruturados são reunidos. Dados estruturados são armazenados em formatos padronizados como CSV, JSON ou XML, enquanto dados não estruturados são armazenados em formatos como PDF, TXT, HTML, imagens e vídeos. O LangChain fornece módulos para processamento de diversos tipos de dados.
2) Geração de Segmentos (chunks): Os dados fonte são processados e divididos em unidades menores, conhecidas como segmentos (ou chunks). Esses segmentos geralmente consistem em frases ou parágrafos. A ideia é que os fragmentos de texto podem ser usados para facilitar o processo de pesquisa e recuperação de informações, no banco de dados vetorial. O LangChain também fornece diversas estratégias segmentação de dados.
3) Incorporação dos segmentos de dados: Os dados de texto a nível de segmento gerados são transformados em representações vetoriais numéricas, através de técnicas conhecidas como embeddings. Este passo envolve mapear os segmentos (ou chunks) em vetores. A OpenAI, através do modelo text-embedding-ada-002, é uma solução comumente empregadas para esse fim.
4) Construção do Banco de Dados Vetorial: O banco de dados vetorial é populado com base nos segmentos criados. Embora o uso de um banco de dados vetorial, há várias vantagens em se utilizar um: primeiro, pois o banco de dados torna a busca por dados semelhantes de forma mais eficiente, segundo pois a aplicação ganha todas as garantias de armazenamento e segurança que um banco de dados fornece. Para tornar as buscas ainda mais eficientes, bibliotecas como o FAISS para indexação vetorial podem ser usadas.
5) Integração de Prompt e Resultados de Pesquisa: Esta etapa envolve a busca de informações com base na pergunta solicitada e a integração de informações relevantes. Para buscar informações contextualmente relevantes com base no prompt, chunks apropriados são recuperados do banco de dados vetorial. Esses chunks são então enviados para LLM para auxiliar no processo de geração de resposta. Por exemplo, em vez de simplesmente enviar uma pergunta, você pode enviar uma pergunta com possíveis chunks de respostas em um mesmo prompt.
6) Geração de Resposta: Usando as informações recuperadas como base, o LLM fica responsável por gerar o texto da resposta. Nesta fase, o tipo, comprimento e estilo linguístico do texto gerado podem ser especificados. Por exemplo, pode-se instruir o LLM no prompt que “Espera-se uma resposta de uma pessoa especialista em apicultura” ou que "Forneça uma reposta de no máximo 50 palavras”.
Outros componentes
Embora os componentes básicos do modelo RAG, como descritos anteriormente, estabeleçam uma base sólida para a criação de uma solução de inteligência artificial conversacional, a inclusão de elementos adicionais pode aprimorar significativamente o desempenho e a eficiência de uma solução baseada em RAG.
Aqui estão alguns desses componentes avançados que podem ser integrados:
1. Chunks mais sofisticados: Em vez de usar apenas segmentos de texto simples, pode-se implementar um sistema mais avançado de “chunks” que utiliza técnicas de processamento de linguagem natural (PLN) para identificar e extrair partes mais significativas do texto. Isso pode envolver análise semântica, reconhecimento de entidades nomeadas ou até mesmo o uso de modelos de atenção para determinar quais partes do texto são mais relevantes para uma dada consulta. Essa abordagem permite uma recuperação de informações mais precisa e contextualizada, melhorando a qualidade das respostas geradas. A biblioteca spacy fornece um excelente desempenho de PLN.
2. Cache de respostas: Implementar um sistema de cache para armazenar respostas frequentemente solicitadas ou previsíveis pode aumentar significativamente a eficiência, além de reduzir o custos de consultas ao LLM. Quando uma pergunta semelhante é feita, o sistema pode rapidamente recuperar a resposta do cache, economizando tempo e recursos computacionais. A biblioteca gptCache implementa um mecanismo de cache semântico.
3. Múltiplas LLMs: Integrar várias LLMs pode oferecer uma gama mais ampla de conhecimentos e estilos de resposta. Por exemplo, pode-se utilizar a OpenAI para perguntas mais gerais, enquanto que pode-se fazer um fine-tunning de LLAMA (open-source e gratuita) para perguntas mais específicas, fornecendo assim melhores respostas, além de reduzindo o custo com LLMs. No entanto, a integração de várias LLMs requer um sistema de orquestração eficiente para determinar qual modelo é mais adequado para responder a uma determinada consulta. O LangChain oferece suporte para gerenciar múltiplas LLMs.
Conclusão
Este texto abordou o potencial transformador dasLLMs no desenvolvimento de serviços baseados em RAG. A combinação do modelo RAG com o LangChain destaca-se como um método robusto e flexível para enfrentar os desafios da geração de respostas precisas e contextualmente relevantes.
Através da exploração dos componentes e procedimentos de uma arquitetura baseada em RAG, destaca-se o processo de coleta e processamento de dados, a geração de segmentos, a incorporação e o armazenamento eficiente em bancos de dados vetoriais. A integração do prompt com os resultados de pesquisa e a geração de respostas ressalta a sofisticação desse modelo na entrega de respostas informadas.
Por fim, existe várias possibilidades de aprimoramento dessa arquitetura, como por exemplo, através da implementação de chunks mais sofisticados, caches de resposta e a utilização de múltiplas LLMs. Essas melhorias não apenas aumentam a eficiência e a precisão, mas também abrem caminho para aplicações mais econômicas e customizadas.