

Entendendo Transformers

Me siga no X | Me siga no LinkedIn | Apoie a Newsletter | Solicite uma consultoria
A ascensão das Inteligências Artificiais Generativas, ou "GenAIs", tem diretamente impactado negócios, governos e indivíduos.
Essas tecnologias de processamento de linguagem natural têm se mostrado capaz de criar textos coesos e contextuais de maneira quase humana, abrindo portas para diversas aplicações, desde a personalização de comunicações com o cliente — através de agentes conversacionais inteligentes— até a geração de conteúdo de marketing envolvente ou programas de computadores sofisticados.
Por trás de tudo isso, GenAIs são impulsionadas por grandes modelos de linguagem (do Inglês, Large Language Models, ou somente LLM). De maneira simplista, um LLM é um mecanismo baseado em redes neurais para aprender uma determinada linguagem. Para isso, oculta-se parte do texto e pede-se à rede neural para predizer as partes faltantes.
Há diversos fatores que ajudam as redes neurais a realizar essas predições. Um destes fatores é o treinamento em extensos conjuntos de dados. Por exemplo, para pre-treinar o LLaMA, do Facebook, foi utilizado todo conteúdo público GitHub, StackExchange, WikiPedia, arXiv, além de milhões de páginas web abertas, resultando em 1.4 trilhões de tokens.
Mas não somente de dados voluptuosos vivem LLMs. Outra característica importante é a capacidade da rede neural prestar atenção seletiva às palavras que compõem o contexto de uma mensagem. Dessa forma, ao processar uma palavra, o mecanismo de “Atenção” habilita o modelo a focar em palavras que tem mais chances de estar relacionadas a palavra processada.
Este mecanismo de Atenção foi uma das descobertas mais importantes nos últimos anos na área de processamento natural de linguagem, introduzida pelo modelo Transformers. De lá pra cá, o mecanismo de Atenção se tornou onipresente em grandes modelos de linguagem, além de ser uma das bases do GPT (do Inglês, Generative Pretrained Transformer) desde sua primeira versão (GPT-1).
Neste texto vamos entender um pouco mais sobre transformers.
📚 Você é dev e quer aprender um pouco mais sobre a criação de aplicações baseadas em LLM?
Eu criei um curso que aborda aspectos teóricos e práticos do desenvolvimento de aplicações baseadas em LLMs. Alguns dos tópicos cobertos:
🟠 O que são e como criar embeddings
🟡 Como selecionar partes relevantes nos seus documentos
🔵 Como integrar essas partes documentos com uma LLM
Arquitetura transformer
Transformers são modelos de IA que revolucionaram o processamento de linguagem. Eles usam atenção contextual para entender relações entre palavras em sequências, impulsionando avanços em tradução, geração de texto e outras tarefas linguísticas complexas.
Os Transformer foram inicial introduzidos no artigo “Attention is All You Need”, por pesquisadores do Google. Desde então, vários modelos, incluindo o BERT, do Google e a série GPT da OpenAI, foram desenvolvidos com base nesse alicerce e publicaram resultados de desempenho que superam com folga os benchmarks de última geração existentes.
Tranformers foram originalmente treinados para tarefas de tradução. Logo, podemos entender um transformer como uma caixa preta que recebe como entrada um texto e retorna como saída esse texto traduzido
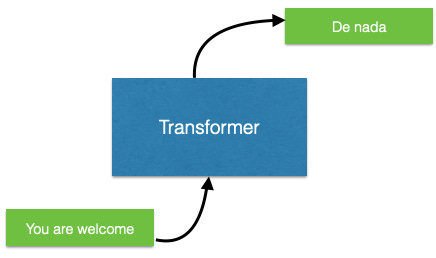
Em seu núcleo, o Transformer contém uma pilha de camadas de codificação (Encoder) e camadas de decodificação (Decoder), além de conexões entre estes elementos. Por fim, há uma camada de saída (Output) para gerar a saída final.
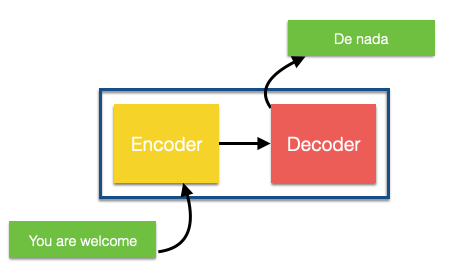
Um encoder nada mais é do que um conjunto de enconders. O encoder recebe uma lista de embeddings como entrada. O componente de decodificação, por sua vez, é um conjunto de decodificadores do mesmo número.
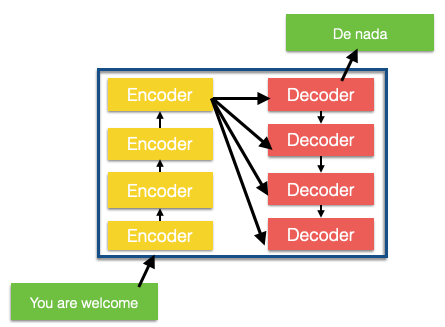
O encoder é responsável por capturar e codificar informações contextuais das palavras de entrada. Cada palavra na sequência de entrada é passada nas camadas de encoders, onde cada camada refina a representação da palavra com base em seu contexto. O processo de um encoder envolve várias etapas:
Representações Iniciais: Cada palavra na sequência de entrada é representada como um vetor numérico (embedding), capturando características básicas como o significado e a posição da palavra na sequência.
Auto-Atenção: A auto-atenção é aplicada em múltiplas camadas do encoder. Para cada palavra, o encoder calcula pesos de atenção em relação a todas as outras palavras na sequência. Isso permite que a palavra capture informações contextuais de palavras próximas e distantes. Iremos abordar esse mecanismos um pouco em frente.
Combinação de Contexto: A partir dos pesos de atenção, o encoder combina as informações contextuais de todas as palavras da sequência, criando uma representação contextualizada para cada palavra. Isso leva em consideração como cada palavra se relaciona com o contexto geral da sequência.
Processamento Feed Forward: Após a auto-atenção, uma camada de processamento feed forward é aplicada a cada representação contextualizada. Essa camada ajuda a refinar as representações, capturando padrões mais complexos e relevantes.
O decoder, por sua vez, é usado para gerar sequências de saída com base nas representações codificadas pelo encoder. O funcionamento de um decoder pode ser descrito da seguinte forma:
Representações do Encoder: O decoder começa recebendo as representações contextuais das palavras da sequência de entrada, geradas pelo encoder. Essas representações são usadas para capturar informações contextuais e relações semânticas.
Auto-Atenção no Decoder: Assim como no encoder, o decoder também utiliza a auto-atenção para ponderar a importância das palavras da sequência de saída em relação a outras palavras da mesma sequência. Isso permite que o modelo considere as palavras anteriores durante a geração autoregressiva.
Geração Autoregressiva: O processo autoregressivo começa gerando a primeira palavra da sequência de saída com base nas representações do encoder e nas saídas anteriores (normalmente começando com um token especial de início). À medida que cada palavra é gerada, ela é incorporada na entrada para gerar a próxima palavra.
Processamento Feed Forward: Após a auto-atenção, uma camada de processamento feed forward é aplicada a cada representação gerada pelo decoder. Finalmente, a saída da camada de processamento é transformada em uma distribuição de probabilidade, o que permite selecionar a palavra mais provável para a próxima posição na sequência.
A camada de decoder é especialmente útil em tarefas como tradução de idiomas, em que a geração da próxima palavra depende das palavras anteriores.
O encoder e o decoder são componentes-chave da arquitetura Transformer. No entanto, tanto o encoder quanto o decoder podem ser vistos como módulos reutilizáveis, habilitando variações na confecção da arquitetura transformer. Algumas arquiteturas do Transformer não têm nenhum decodificador e dependem apenas do codificador. Dentre as principais arquiteturas, estão:
Somente com encoder
Somente com decoder
Com encoder e decoder
De acordo com um estudo recente, dentre as arquiteturas transformers, a que utiliza somente o decoder tem se tornado uma escolha mais popular recentemente. Algumas razões para essa preferência incluem:
Simplificação do uso: Modelos que empregam apenas decoders são relativamente mais simples de treinar e usar do que os modelos que possuem componentes complexos de codificação e decodificação. Isso facilita sua adoção em diferentes contextos.
Geração de Texto Coerente: A pilha de decoders é altamente adequada para tarefas de geração de texto, como completar frases, escrever histórias e responder a perguntas. A abordagem autoregressiva permite que o modelo gere sequências de saída palavra por palavra, levando em consideração o contexto anterior. Isso resulta em textos fluentes e coerentes.
Mecanismo de Auto-Atenção
A chave para o desempenho das arquiteuras Transformer é o uso da camada de Auto-Atenção. Ao contrário das abordagens convencionais que tratam as palavras de maneira independente, a auto-atenção considera a interdependência entre todas as palavras em uma sequência.
Este mecanismo permite que palavras em uma frase se relacionem e influenciem umas às outras de maneira contextual. A auto-atenção calcula pesos para todas as palavras em relação a uma determinada palavra, ponderando sua relevância.
Por exemplo, na frase “O gato estava na árvore”, ao calcular a representação para a palavra “gato”, a auto-atenção considera todas as outras palavras (“O”, “estava”, “na”, “árvore”), atribuindo diferentes pesos com base em suas conexões contextuais. Isso permite ao modelo entender que o “gato” está mais relacionado a palavra “árvore” do que a palavra “O”, capturando as relações semânticas.
A auto-atenção também é útil para resolver ambiguidades, como em “Vi o homem com o telescópio”. Aqui, o modelo percebe que a palavra “com” se relaciona mais fortemente com a palavra “telescópio” do que com a palavra “homem”, proporcionando uma compreensão precisa.
Para cada palavra em uma frase, a auto-atenção calcula três vetores, chamados de consulta (query), chave (key) e valor (value). Esses vetores são gerados a partir das palavras vizinhas e permitem que o modelo avalie a relevância de cada palavra em relação às outras.
A relevância é medida por meio de produtos escalar (uma medida de proximidade) entre a consulta (query) e as chaves (keys). O resultado é um conjunto de pesos de atenção, que indicam quanto cada palavra contribui para a representação da palavra de consulta. Isso permite que o modelo pondere a influência das palavras circundantes, dando mais importância a palavras relevantes em diferentes contextos.
Implementações de transformers
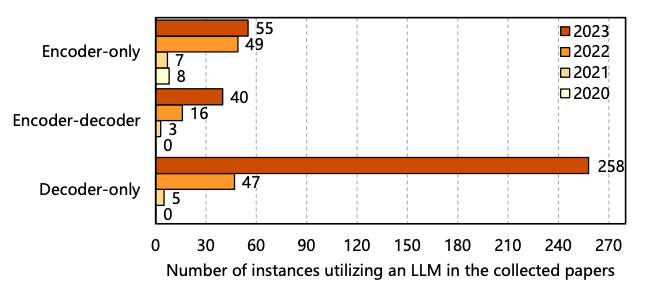
De acordo com uma revisão da literatura sobre LLMs, o ano de 2022 marcou um aumento no desenvolvimento de LLMs somente de decodificador, uma tendência que ganhou mais impulso em 2023, principalmente com o lançamento de produtos comerciais pelas principais empresas de tecnologia. Por exemplo, o Google lançou o Bard, a Meta apresentou o LLaMA e o LLaMA 2, e a OpenAI ganhou destaque mundial lançando a familia de modelos GPT.
A figura abaixo, retirada do artigo que estou uso de LLMs na engenharia de software, apresenta o uso desses diferentes tipos de arquitetura de LLMs ao longo dos anos.

Para utilizar algumas dessas (e várias outras) implementações, pode-se utilizar a biblioteca HuggingFace. Por exemplo, podemos construir um prompt usando o GPT-2, do OpenAI. Rode o exemplo abaixo e veja o quanto esses modelos evoluiram em tão pouco tempo.
!pip install xformers accelerate transformers
from transformers import pipeline
model = "gpt2"
generator = pipeline('text-generation', model=model)
generator("Hello, I'm studying about transformers in AI, they are", max_length=30, num_return_sequences=5)Uma das vantagens do HuggingFace é que diversos LLMs estão disponíveis; logo, utilizar outro LLM é apenas questão de mudar o valor da variável modelo.