

K-Means e o aprendizado não supervisionado
K-Means e o aprendizado não supervisionado
Aprendendo a classificar dados sem precisar de rótulos

K-Means e o aprendizado não supervisionado
Me siga no X | Me siga no LinkedIn | Apoie a Newsletter | Solicite uma consultoria
A classificação é um processo onde um algoritmo é treinado para categorizar dados em diferentes classes ou rótulos com base em suas características que foram fornecidas em amostras de dados de treinamento.
Algoritmos de classificação analisam os dados de entrada e constroem um modelo que identificam as classes (ou rótulos) presentes dos dados. Quando os rótulos das amostras não são fornecidas pelo usuário, estes podem ser previstos usando algoritmos não-supervisionados de classificação. Uma das técnicas de classificação com algoritmos não supervisionados é o K-Means.
O K-Means é um algoritmo popular para tarefas de clustering. Ele agrupa dados em K clusters, onde K é um número de clusters predefinido pelo usuário. Além do valor de K, há uma segunda variável que pode impactar no desempenho do algoritmo: o calculo de distância. A distância entre dois pontos de dados é determinada pelo cálculo da matriz de distância, onde a Distância Euclidiana é a função de matriz de distância mais amplamente utilizada.
Nesse texto, vamos aprender mais sobre o k-means e como utiliza-lo.
📚 Você é dev e quer aprender um pouco mais sobre a criação de aplicações baseadas em LLM?
Eu criei um curso que aborda aspectos teóricos e práticos do desenvolvimento de aplicações baseadas em LLMs. Alguns dos tópicos cobertos:
🟠 O que são e como criar embeddings
🟡 Como selecionar partes relevantes nos seus documentos
🔵 Como integrar essas partes documentos com uma LLM
Aprendizado não-supervisionado
O aprendizado não supervisionado é uma abordagem fundamental do aprendizado de máquina, onde os algoritmos são treinados para descobrir padrões ocultos nos dados, sem orientação de usuários externos.
Diferentemente do aprendizado supervisionado, onde os algoritmos são treinados com dados rotulados para fazer previsões ou classificações, o aprendizado não supervisionado opera principalmente em dados não rotulados.
Um dos principais métodos do aprendizado não supervisionado é o clustering, que envolve agrupar dados semelhantes em clusters (ou grupos). O algoritmo K-Means é um exemplo notável de técnica de clustering. Esses algoritmos tendem a encontrar padrões na estrutura dos dados como forma de tomar suas decisões.
K-Means
O K-Means é um algoritmo de agrupamento, onde os dados são inseridos em um número de K clusters. O número de clusters (K) é fornecido pelo usuário, no início do processo.
Os K clusters não são definidos aleatoriamente; são identificados através de centroides —ou ponto central—, que são pontos representativos no espaço de dados utilizados para definir os clusters.
Os centroides no algoritmo K-Means são definidos considerando as distâncias dos dados. O algoritmo analisa as distâncias entre os dados da amostra e agrupa aqueles com distâncias menores, indicando sua similaridade. As distâncias são calculadas como métodos como distância euclidiana, manhattan, minkowski ou outras medidas de similaridade, podendo variar de acordo com a natureza dos dados ou contexto do problema.
Os centroides podem ser escolhidos tanto aleatoriamente, como utilizando estratégias de busca refinadas. Após a inicialização, o algoritmo calcula as distâncias entre cada ponto de dados e os centroides iniciais. Durante cada iteração do K-Means, os pontos de dados são atribuídos aos clusters com base na proximidade ao centróide mais próximo.
Uma vez que todos os pontos são atribuídos aos clusters, os centroides são recalculados como a média dos pontos atribuídos a cada cluster. Este novo centróide representa o ponto central dos dados atribuídos ao cluster, minimizando a soma das distâncias entre os pontos e seus centroides associados.
K-means na prática
Para utilizar o K-means, podemos usar a implementação disponível na biblioteca sklearn.
Definindo nossos dados
Antes, no entanto, vamos iniciar nosso conjunto de dados. Para esse exemplo, vamos considerar duas variáveis hipotéticas de um projeto de desenvolvimento de software: quantidade_de_pessoas, que define o tamanho da equipe do projeto (que pode variar entre 2 e 20 pessoas) e quantidade_de_dias, que define o tempo de execução. do projeto (que pode variar entre 90 e 900 dias).
import numpy as np
from sklearn.cluster import KMeans
np.random.seed(42)
quantidade_de_pessoas = np.random.randint(2, 21, size=20)
quantidade_de_dias = np.random.randint(90, 901, size=20)
dados = np.column_stack((quantidade_de_pessoas, quantidade_de_dias))Após gerar esses dados, podemos criar uma figura para observar sua distribuição.

Podemos ver na imagem que os 20 pontos que representam os projetos de software estão distribuídos sem seguir um padrão claro. Há, por exemplo, dois projetos com muitas pessoas mas com poucos dias de execução (18 pessoas e 100 dias de duração e 13 pessoas e 110 dias de duração), enquanto há dois projetos com poucas pessoas, mas com relativamente alto tempo de execução (3 pessoas e 736 dias de duração e 2 pessoas e 477 dias de duração).
Treinamento e teste
Após definir os dados, podemos criar nosso modelo e pedir para que ele faça predições com base nos dados fornecidos. Para ajudar o modelo, precisamos informar quantos clusters gostaríamos de criar. Para esse exemplo, utilizaremos 3 clusters.
numero_de_clusters = 3
kmeans = KMeans(n_clusters=numero_de_clusters)
grupos = kmeans.fit_predict(dados)Diferente de algoritmos supervisionados, no K-means, um algoritmo não-supervisionado, não se faz necessário separar os dados em processo de treino e teste. Isso acontece pois em algoritmos supervisionados, o processo de treino é utilizado para que o algoritmo possa aprender quais são os rótulos disponíveis e, então, tentar predizer o rótulo na etapa de teste. Como não fornecemos rótulos para o K-Means, utilizamos o método fit_predict, em vez de chama-los individualmente (primeiro fit, depois predict).
Identificação de centroides
Após a execução do modelo, armazenamos a predição do algoritmo na variável grupos. Com os grupos definidos, podemos obter quais foram os centroides identificados. Para isso, basta acessar a variável cluster_centers_:
centroides = kmeans.cluster_centers_Centroides são posições centrais no espaço dos dados, representando os pontos que melhor indicam a formação de um cluster. Essencialmente, os centroides são as “médias” dos pontos dentro de um cluster, tornando-se representantes ideais do grupo.
Com a identificação dos centroides, podemos plota-los em cima da figura com nossos dados. Os centroides estão marcados com um “X” vermelhos no gráfico, indicando as posições centrais ao redor das quais os dados foram agrupados. Eles são fundamentais para entender a estrutura e a distribuição dos clusters no espaço de características.
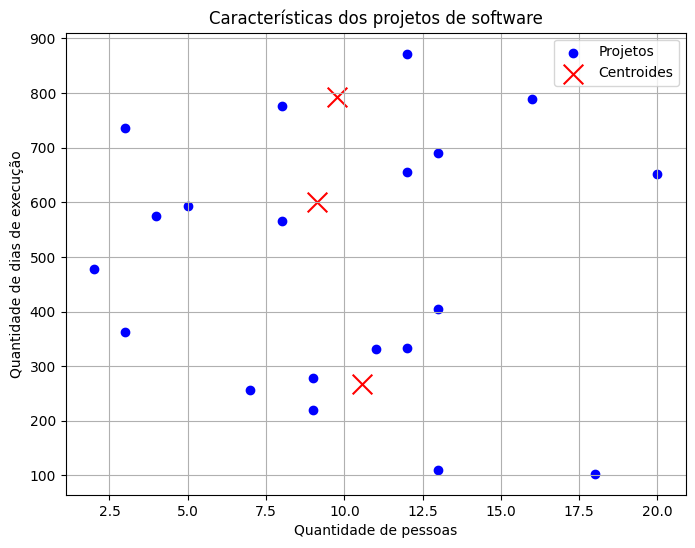
Visualizando clusters
Em um modelo KMeans, cada item de dado é associado a um centroid, representando o centro de um cluster específico. A relação entre itens de dado e centroides é fundamental para entender como os dados são agrupados.
A figura abaixo oferece uma visualização clara, destacando quais itens de dado pertencem a quais centroides. Esta associação é crucial para determinar a qual cluster um dado específico pertence, formando a base para análises os padrões observados.

Conclusão
No processo de agrupamento de dados, o algoritmo K-Means destaca-se ao encontrar padrões em conjuntos complexos de informações. Ao atribuir cada dado a um centroid, o K-Means proporciona uma visão estruturada do conjunto, permitindo análises detalhadas e tomadas de decisão embasadas.
A precisão do modelo é evidenciada pela clareza com que os itens de dados são associados aos seus respectivos centroides, delineando agrupamentos claros e significativos. O KMeans, ao revelar padrões ocultos, desempenha um papel importante no aprimoramento da compreensão dos dados, impulsionando a descoberta e inovação em várias disciplinas.
Para acessar o código apresentado nesse texto, clique aqui.