
Utilizando o ChatGPT como ferramenta de correção automática de questões técnicas

Me siga no X | Me siga no LinkedIn | Apoie a Newsletter | Solicite uma consultoria
A indústria de software impõe desafios regulares as equipes de pessoas desenvolvedoras. Empresas e equipes buscam constantemente melhorar sua eficiência operacional, através da diminuição de custos, embora mantendo (ou aumentando) sua velocidade e produtividade.
Pessoas desenvolvedoras de software precisam estar continuamente se aperfeiçoando, de forma a se manterem relevantes em suas carreiras.
Durante o processo de estudo e treino de uma nova tecnologia, a resolução prática de atividades de programação tem um papel importante para o desenvolvimento das novas capacidades, por pelo menos dois motivos.
Primeiro, ajudam na fixação e autoavaliação do conhecimento ao aprender algum conceito novo.
Segundo, podem indicar se o conhecimento atual da pessoa avaliada é adequado para realização das suas atividades
No entanto, tão importante quanto a resolução dos exercícios é o feedback de avaliação das questões que as pessoas desenvolvedoras recebem em relação aos exercícios.
No entanto, fornecer bons feedbacks é desafiador, pois requer que a pessoa que fornece o feedback 1) tenha amplo conhecimento sobre assunto, 2) esteja disponível para fornece-lo e, 3) saiba identificar lacunas de conhecimento de forma a maximizar os pontos que precisam ser endereçados pelo estudante.
Uma vez que o feedback das correções é feito de maneira manual, o feedback se torna também sensível a escala da quantidade de correções que precisam ser feitas.
Isso se torna ainda mais desafiador no contexto de empresas de software, que geralmente não contam com suficiente profissionais dedicados para fornecer feedbacks de exercícios técnicos.
Neste texto, revisamos um artigo científico que conduziu experimento da construção de um mecanismo para correção e feedback automático de questões técnicas utilizando o ChatGPT. Essa avaliação foi feita junto a uma empresa de tecnologia nacional.
O objetivo desse experimento era entender até que ponto o ChatGPT poderia ser considerado como mecanismo oficial de correções de questões técnicas abertas do processo de treinamento empregado pela empresa parceira.
Neste textos, vamos abordar:
Por que usar o ChatGPT para correções de questões técnicas?
Como foi feito esse experimento?
Posso usar o ChatGPT como ferramenta de correção de provas?
Por que usar o ChatGPT?
O ChatGPT é uma implementação específica de um LLM baseado na arquitetura GPT, com o potencial de promover melhorias no aprendizado e nas experiências de ensino em diferentes níveis, desde o ensino escolar até o universitário e o desenvolvimento profissional.
Uma das vantagens do ChatGPT, assim como outros LLMs, é a capacidade de oferecer aprendizado personalizado, levando em consideração as preferências, habilidades e necessidades individuais de cada aluno.
Essa personalização pode contribuir para tornar a experiência de aprendizado mais efetiva.
Como foi feito esse experimento?
Realizamos esse experimento em duas etapas.
Primeiro, pedimos para que pessoas especialistas respondessem seis questões abertas. Essas questões foram corrigidas utilizando o ChatGPT. Para fins de comparação, também pedimos para o ChatGPT responder as mesmas questões; e também corrigimos as questões respondidas pelo ChatGPT com o ChatGPT.
Depois de refinar as respostas das seis questões, em seguida, pedimos para que um grupo maior de pessoas desenvolvedoras, porém sem especialidade na área das questões, respondessem as questões.
Para manter a concisão de um texto de blog, iremos nesse texto abordar somente a primeira parte do estudo. Para aqueles interessados em entender os detalhes adicionais da pesquisa, o estudo completo está disponível neste link.
Definição das questões técnicas
Selecionamos dois temas nos quais tínhamos especialistas para escrever respostas: caching de aplicações WEB e teste de estresse e desempenho.
Com as respostas dos especialistas, nossos prompts comparariam estas respostas com as respostas dos participantes do experimento, diminuindo o viés de confirmação conhecido no ChatGPT.
Escolhemos três questões de cada tema. As questões foram organizadas em ordem crescente de dificuldade, começando com a mais fácil e terminando com a mais difícil.
As questões escolhidas foram:
Caching
Q1: Explique com suas palavras o que você entende sobre caching de aplicações REST?
Q2: Explique brevemente o funcionamento dos dois tipos de caching?
Q3: Explique o invalidação de cache em aplicações REST e apresente uma forma de resolve-lo?
Teste de estresse e desempenho
Q4: Explique o conceito de teste de carga e estresse?
Q5: Quais são as principais métricas utilizadas para avaliar o desempenho de uma aplicação durante um teste de carga?
Q6: Quais são as melhores práticas para realizar testes de carga em aplicações que expõem APIs REST?
Envio das questões aos participantes
Enviamos o questionário para uma população de 100 pessoas da empresa parceira que já haviam participado de ao menos um dos treinamentos técnico recentemente. Após duas semanas, tivemos 40 respostas.
Engenharia de prompt
O termo prompt se refere a um conjunto de instruções que são fornecidas para um LLM como forma a customizar ou refinar suas capacidades. O prompt define o contexto da conversação, avisa ao LLM qual informação é importante, bem como qual tipo de saída é esperada. A qualidade da saída gerada por um LLM está diretamente relacionada a qualidade do prompt fornecido pelo usuário.
O processo de engenharia de prompts envolve a modificação dos prompts de forma a obter resultados mais desejáveis. Essa técnica otimiza a interação humano-computador, refinando a geração de texto com base nas necessidades e expectativas dos usuários.
Nesse estudo, fizemos diversas iterações na criação do prompt para correção de questões técnicas.
Na primeira versão de prompt, utilizamos o ChatGPT como oráculo para as questões abertas. Além disso, mencionamos aspectos técnicos que embora sejam relavantes para o contexto da empresa, não eram necessários para responder as questões abertas.
Em seguida, na tentativa de aumentar o rigor da avaliação do modelo, adicionamos a seguinte instrução: “Eu preciso que você realize correções de provas usando a régua de correção mais alta que você puder.”
Por fim, adicionamos uma última instrução ao final do prompt, indicando que “Sempre que possível, a explicação deve conter exemplos reais”.
O prompt final que elaboramos foi:
Eu preciso que você realize correções de provas usando a régua de correção mais alta que você puder.
Considere a seguinte questão e a seguinte resposta de um especialista:
Q: Explique com suas palavras o que você entende sobre caching de aplicações REST?
R especialista: caching é uma técnica que permite armazenar dados que são acessados frequentemente em memória, afim de reduzir o custo de complexidade da consulta dos mesmos. Hoje em dia existem diversas formas de aplicar caching em REST APIs, iniciando ao lado do servidor através de técnicas de cache local e distribuído. E também é possível habilitar o caching ao lado cliente, onde através do uso de cabeçalhos do protocolo HTTP, é definido politicas que regem o comportamento do caching}, como por exemplo, o uso de versões, tempo de expiração e também definir quais clientes podem armazenar os dados, no caso referindo ao navegador do usuário final e/ou CDNs.
Agora, considere a resposta de um aluno, fornecida abaixo.
R aluno: {}
Qual nota você daria para a resposta do aluno, levando em consideração a resposta do especialista, numa escala de 0 a 10?
Devolva a resposta em um formato JSON, com uma variável ‘nota’, com a sua nota, e uma outra variável ‘explicacao’ com a explicação para esta nota.
Sua explicação deve ter ao menos 20 palavras. Na explicação, identifique lacunas de conhecimento e explique de forma que minimize essa lacuna, utilizando exemplos reais.
Se nenhuma resposta for informada, informe que ‘Nenhuma resposta foi informada’, e de nota zero.
Métricas de avaliação de qualidade
O ChatGPT, assim como outros LLMs, conta com uma conhecida limitação referente a percepções falsas ou distorcidas de informações geradas pelo próprio modelo. Essas alucinações podem fazer com que o LLM gere resposta que pareçam corretas, quando na verdade não são.
Como forma de minimizar essa limitação e complementar a correção fornecida pelo ChatGPT, calculamos também a métrica de similaridade de cossenos, entre a resposta fornecida pelo especialista e a resposta fornecida pelo participante do estudo.
Ao calcular a similaridade de cossenos entre as respostas dos participantes e um gabarito de referência (resposta do especialista), é possível obter uma medida objetiva de quão próximas as respostas estão do padrão desejado.
Podemos usar o ChatGPT para corrigir provas?
Tentamos responder essa pergunta por diferentes ângulos.
Inicialmente, solicitamos ao ChatGPT que corrigisse as respostas fornecidas pelos especialistas. Como resultado, a resposta do especialista foi corrigida como se fosse a resposta de um aluno.
Após coletar e corrigir as respostas dos especialistas com o ChatGPT, solicitamos ao ChatGPT que respondesse às seis questões abertas. Essas respostas fornecidas pelo ChatGPT foram, em seguida, corrigidas também pelo ChatGPT.
O resultado dessa correção está disponível na imagem abaixo.
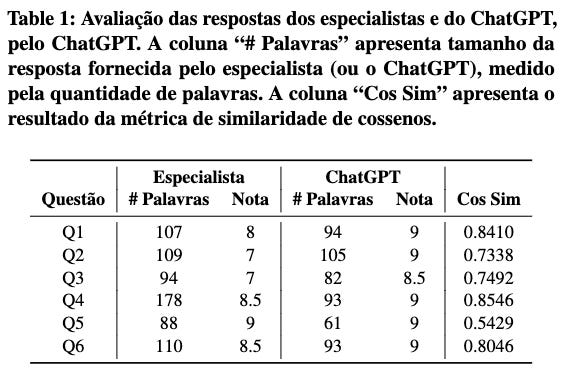
Correções das respostas dos especialistas pelo ChatGPT
Como é possível perceber, as respostas do primeiro grupo de perguntas sobre caching (Q1, Q2 e Q3) foram consistentemente menores do que as do segundo grupo.
Ao analisar os feedbacks fornecidos pelo ChatGPT, observamos comentários que podem ter influenciado as notas recebidas. Por exemplo, ao considerar o primeiro conjunto de respostas sobre caching, o ChatGPT indicou que as respostas apresentavam conceitos básicos, mas não os explicavam ou exemplificavam de maneira adequada.
Na Q2, que recebeu nota 7 e questionava sobre a diferença entre cache do lado do cliente e do lado do servidor, o especialista explicou sobre o cache do lado do servidor, mas não mencionou a segunda abordagem, o cache do lado do cliente. O ChatGPT identificou essa lacuna e destacou-a em sua correção.
Outro exemplo interessante para destacar é a explicação fornecida para a Q5, que questiona sobre as principais métricas de teste de carga. Nesta explicação, o ChatGPT indicou que: “A resposta do aluno abordou corretamente as métricas response time, throughput e error rate, mencionou o RED Method e citou exemplos de outras situações. Contudo, poderia ter explicitado a relação dessas métricas com a experiência do usuário e mencionado métricas mais específicas para outras aplicações, como índices de latência para sistemas de tempo real”. Ou seja, o ChatGPT foi capaz de identificar corretamente os itens fornecidos nas respostas, mas não identificou uma possível relação entre estes itens—mesmo embora esta relação não tenha sido questionada na pergunta.
Percepção da correção do ChatGPT pelos especialistas
Em seguida, enviamos as correções fornecidas pelo ChatGPT para os especialistas que escreveram as respostas.
Quando questionamos se os especialistas concordam com as avaliações fornecidas, em geral, eles concordaram com as avaliações. Em particular, na questão Q3, em que houve uma maior discordância entre as respostas dos especialista e do ChatGPT, o especialista que forneceu a resposta comentou que: “[nesta questão] ele foi cirúrgico, e percebeu que minha resposta estava incompleta. Eu acredito que a nota foi mais alta do que deveria. Eu mesmo me daria uns 5.”
No entanto, na Q4 observou-se um ponto de discordância, uma vez que o especialista comentou que “Essa explicação não faz muito sentido, pois o que ela diz que não tem na resposta de fato está lá”, referindo-se a diferença entre teste de carga e teste de desempenho.
Correções das respostas do ChatGPT pelo ChatGPT
De maneira geral, as respostas fornecidas ChatGPT tiveram nota superiores, quando comparado as respostas fornecidas pelos especialistas.
Em particular, a diferença foi maior no grupo de questões sobre caching: 2 pontos de diferença para a questão Q2 e 1.5 pontos de diferença na questão Q3.
No entanto, para o segundo grupo de perguntas sobre teste de estresse e desempenho, foi observado uma variação menor entre as notas do especialista e as notas do ChatGPT: somente 0.5 pontos na Q4 e também 0.5 pontos na Q6.
Correção das respostas dos alunos
Após a avaliação individual das respostas dos especialistas, seguimos para a avaliação das respostas dos participantes do estudo.
Nossa hipótese inicial era de que os participantes que haviam completado ao menos um treinamento técnico teriam menos dificuldade em responder as questões (atestado pelas maiores notas).
No entanto, para as questões Q1 e Q2 foi possível observar que os participantes que completaram ao menos um treinamento obtiveram ao menos um ponto a mais daqueles que não completaram nenhum treinamento.
Por outro lado, para as questões Q3 e Q6, os participantes que não concluíram nenhum treinamento obtiveram notas superiores, quando compara aqueles que terminaram um treinamento.
Confiabilidade nas correções fornecidas pelo ChatGPT
Como forma de complementar as correções fornecidas pelo ChatGPT, calculamos a métrica de similaridade de cossenos.
Para a maioria das questões, observamos uma tendencia entre as notas fornecidas pelo ChatGPT e a métrica de similaridade de cossenos.
Dentre as 40 respostas, somente 10 tiveram mais de 3 pontos de divergência entre o ChatGPT e a métrica de similaridade de cossenos.
Ao analisar essas respostas, percebemos que o ChatGPT foi capaz de detectar detalhes na resposta, que potencialmente direcionaram a nota gerada. Por exemplo, um participante respondeu a Q5 da seguinte forma: “tempo de resposta, quantidade de dados transferidos e taxa de sucesso(throughput) e taxa de erro”.
No entanto, o ChatGPT observou a confusão que o participante fez entre taxa de sucesso e throughput: “A resposta do aluno aborda as métricas principais, com algumas incorreções. Ele menciona o tempo de resposta, throughput e taxa de erros, mas confunde quantidade de dados transferidos com throughput. Para clarear, throughput geralmente se refere à quantidade de operações por unidade de tempo e não à quantidade de dados transferidos. [...]”.
Em outras palavras, embora o participante tenha usado os termos corretos, a semântica dos termos estava incorreta. Isso pode ter enviesado a métrica, embora o ChatGPT tenha sido capaz de detectar e corrigir.
Concluindo
Nesse estudo preliminar, foi possível observar o destaque do uso do ChatGPT para correções de questões técnicas abertas. Em particular, as pessoas especialistas concordaram com as correções fornecidas pelo ChatGPT.
Além disso, em uma análise mais qualitativa, foi possível perceber que o ChatGPT foi capaz de fornecer avaliações mais precisas, quando comparado a outras métricas mais tradicionais, como a de similaridade de cossenos.
Para entender mais dos detalhes da pesquisa, não deixe de conferir o artigo completo.